本篇文章不是讲ElasticSearch(下面简称ES)聚合分析的基本概念和用法的,这些网上的资料很多,不清楚的可以自行查阅。
我下面聚合分析使用的数据都是kibana自带的,这样方便有些读者实际测试文中的示例。
基本概念
ES为了满足搜索的实时性,在聚合分析的一些场景会通过损失精准度的方式加快结果的返回。这其实ES在实时性和精准度中间的权衡。
需要明确的是,并不是所有的聚合分析都会损失精准度,比如min,max等这些就没有精准度的问题。
可能这样直接说不好理解,下面会有详细的分析。
问题描述
我们通过一个示例引入问题。
首先我会把kibana自带的航班信息索引(名为kibana_sample_data_flights)reindex到我自定义的一个索引(名为my_flights)中,我的mapping和自带的索引完全一样,唯一的区别在于我设置了20个分片。索引的设置如下:
PUT my_flights
{
"settings": {
"number_of_shards": 20
},
"mappings" : {
"properties" : {
"AvgTicketPrice" : {
"type" : "float"
},
省略其它部分reindex(以后有专门的文章讲reindex)的过程比较慢,我的电脑大概需要一分钟左右。
POST _reindex
{
"source": {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "my_flights"
}
}然后我们执行聚合分析的查询,这个查询是根据航班的目的地进行分桶。
GET my_flights/_search
{
"size": 0,
"aggs": {
"dest": {
"terms": {
"field": "DestCountry"
}
}
}
}结果如下,
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 20,
"successful" : 20,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dest" : {
"doc_count_error_upper_bound" : 52,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
{
"key" : "US",
"doc_count" : 1987
},
其它部分省略在返回结果的aggregations中,有两个值:doc_count_error_upper_bound和sum_other_doc_count,我先来解释下,
doc_count_error_upper_bound:表示没有在这次聚合中返回,但是可能存在的潜在聚合结果。
sum_other_doc_count:表示这次聚合中没有统计到的文档数。这个好理解,因为ES统计的时候默认只会根据count显示排名前十的分桶。如果分类(这里是目的地)比较多,自然会有文档没有被统计到。
而这个doc_count_error_upper_bound就是我们本文要关注的重点对象,这个指标其实就是告诉用户本次的聚合结果究竟有多不精确。
问题分析
ES基于分布式,聚合分析的请求都是分发到所有的分片上单独处理,最后汇总结果。ES的terms聚合本身是前几个(size指定)结果,这就导致了结果必然有误差。
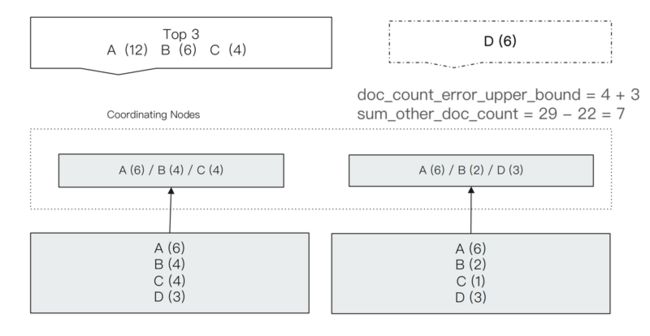
如上图所示,我们进行一个terms分桶查询,取前面3个结果。ES给出的结果是 A,B,C三个term,文档数量分别是12, 6, 4。
但是我们看最下面两个分片上的文档分布,人工也能看出来其实D应该是在结果中的,因为D的文档数量有6个,比C多,所以比较精确的结果应该是A,B,D。
产生问题的原因在于ES在对每个分片单独处理的时候,第一个分片的结果是A,B,C,第二个分片是A,B,D,并且第一个分片的C的文档数量大于D。所以汇总后的结果是A,B,C。
如何提高精准度
讨论完了问题,现在来看看如何解决问题。一般的方案有几种:
不分片
设置主分片为1,也就是不分片了。这个显而易见,上面分析聚合不精确的核心原因就在于分片,所以不分片肯定可以解决问题。但是缺点也是显然的,只适用于数据量小的情况下,如果数据量大都在一个分片上会影响ES的性能。
我们来做个测试,看看不分片的效果。我们使用自带的kibana_sample_data_flights索引来执行分桶聚合。
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"dest": {
"terms": {
"field": "DestCountry"
, "size": 3
}
}
}
}结果是,
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 7605,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
其它部分省略因为kibana_sample_data_flights索引的分片数量是1,所以没有损失精准度。
提高聚合的数量
如下所示,把size设置成20(默认情况是10)聚合查询。size是指定聚合返回的结果数量。返回的结果越多,精确度肯定就越高。
GET my_flights/_search
{
"size": 0,
"aggs": {
"dest": {
"terms": {
"field": "DestCountry"
, "size": 20
}
}
}
}结果,
"aggregations" : {
"dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 571,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
其它部分省略结果也是没有精准度的损失了。
调大shard_size值
这个值表示要从分片上拿来计算的文档数量。默认情况下和size是一样的。取得size的值越大,结果会越接近准确,不过很明显会影响性能。
总结
ES某些聚合统计会存在损失精准度的问题
损失精准度的原因是分片处理中间结果,汇总引起的误差,是ES实时性和精准度的权衡
可以通过调大shard_size等方法增加精准度

最新评论: